Method
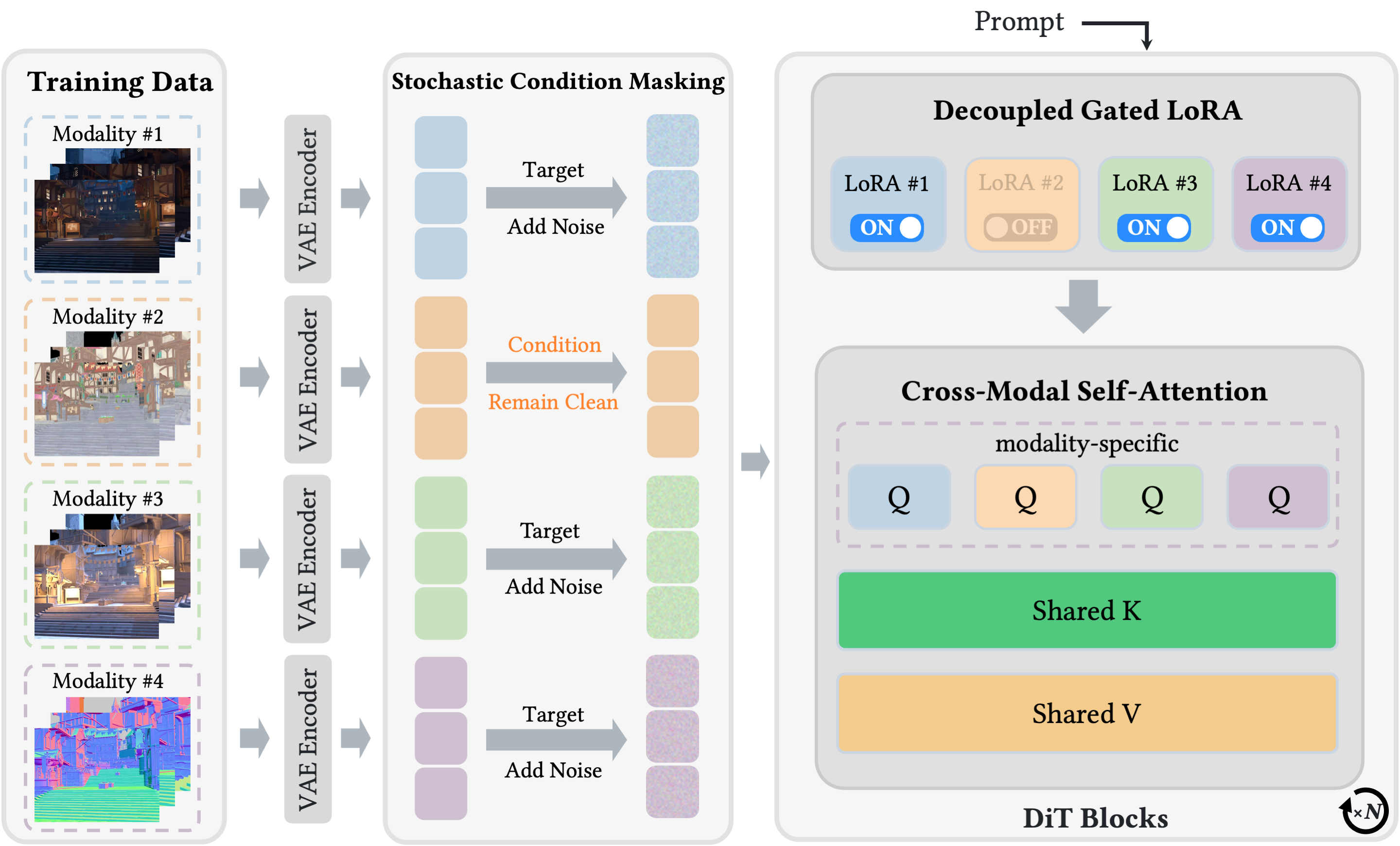
Stochastic Condition Masking (SCM)
- Randomly masks modalities during training.
- Enables omni-directional video generation.
Decoupled Gated LoRA (DGL)
- Decoupled, Per-modality LoRA adapters.
- Gate ON when modality is a Target, OFF when modality is a Condition.
Cross-Modal Self-Attention (CMSA)
- Shared Keys/Values and modality-specific Queries.
- Accelerates cross-modal alignment.